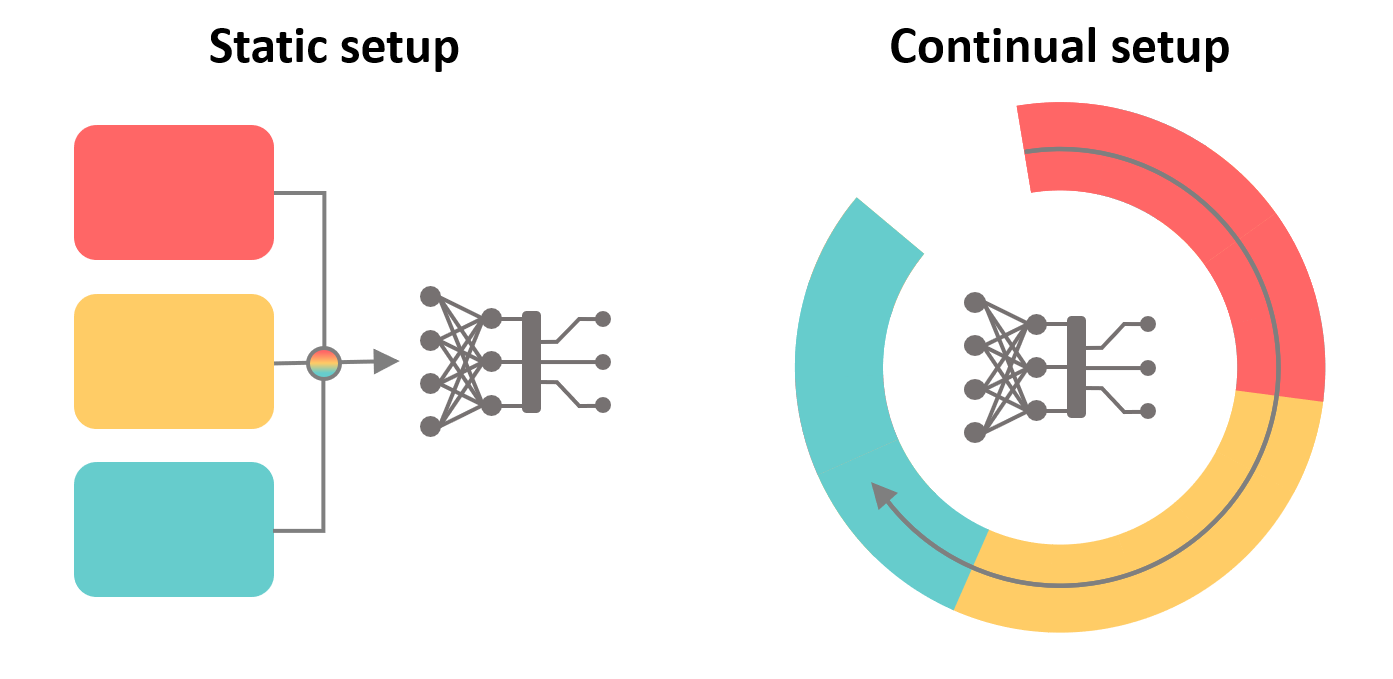
Der übliche Arbeitsablauf bei der Umsetzung von Methoden der künstlichen Intelligenz besteht aus 1) dem Training des Modells 2) Auswertung und 3) Einsatz. Annotierte Daten werden durcheinandergemischt und unterteilt in Train- und Testdaten. Bei diesem Arbeitsablauf wird nicht berücksichtigt, dass während des Einsatzes Trainingsdaten verfügbar werden könnten.
Unter kontinuierlichem Lernen versteht man den sequentiellen Empfang von kleinen Datenmengen aus unterschiedlichen Quellen. Im Gegensatz zum üblichen Arbeitsablauf können kontinuierlich lernende Algorithmen nacheinander eintreffende Daten verarbeiten, die eventuell nur für einen kurzen Zeitraum verfügbar sind. Sie weisen eine gute Leistung bei allen Daten auf, die während des Trainings beobachtet wurden, unabhängig davon, wann diese Daten zum Training des Systems verwendet wurden.